Mining HTTP requests from client-side JS with static analysis
Here in Computer Security Lab we are working on a client-side JavaScript code analysis algorithm for discovering HTTP requests that can be sent by that code to server (AJAX requests). The goal is to then give this information to a web security scanner working in black-box mode (without server source code access). So that the scanner knows which requests are accepted by the server and, therefore, where to insert the attack vectors. We are ourselves making a web security scanner SolidPoint that uses this analysis algorithm. In this post (and in the next couple), I’ll talk about this analysis: why did we start making it, how does it work and what do we get as a result. I’ll also share a link to the analyzer’s source code — we’ve made it public!
By the way, we’ve published a couple of scientific papers about it (here is one of them, and here is another).
Why
Why did we decide to work on this? For a long time now we have been doing penetration tests. And during those, we were periodically noticing places in client-side JS where requests were sent to server endpoints, which were not accessed anywhere in the user interface. Sometimes there was a piece of JS on the page sending requests related to admin panel actions (while we were not logged in as an administrator), sometimes all client-side code of the website was bundled together and present on a page. And there were cases when authorization checks for those endpoints were missing on the server and, in those cases, if we were able to find the endpoint in JS, we could perform the corresponding action even though our user should not have had access to it (and admin panels were sometimes susceptible to such bugs). To find those cases, we were reading the client-side code and figuring out what requests were sent from it. So our thought was: maybe we can automate that?
Finding requests sent by HTML elements is rather easy, but with JS it gets harder. To determine which requests the client-side JS sends, scanners typically use dynamic crawling. Dynamic crawling is interacting with website pages using a headless browser (such as Headless Chrome). This often works well, but such a method won’t find the requests that we wanted to discover — for those requests there were no interface elements to interact with. Only the JS that was unintentionally left on the page. Moreover, dynamic crawlers sometimes have problems even with requests that are accessible from the UI. The user interface can be rather complicated, with a lot of possible interactions. A crawler, in general, does not know which combinations of those interactions would lead to sending requests. To find a request triggered by a sequence of interface actions a crawler may have to try too many things to perform in a reasonable time.
So we decided to create something that will discover the requests without interacting with the UI, but by means of looking at the client-side code itself. JavaScript code analyzer. We chose to start with static analysis — static analysis is able to cover all parts of the code regardless of how difficult it is to reach them in real execution.
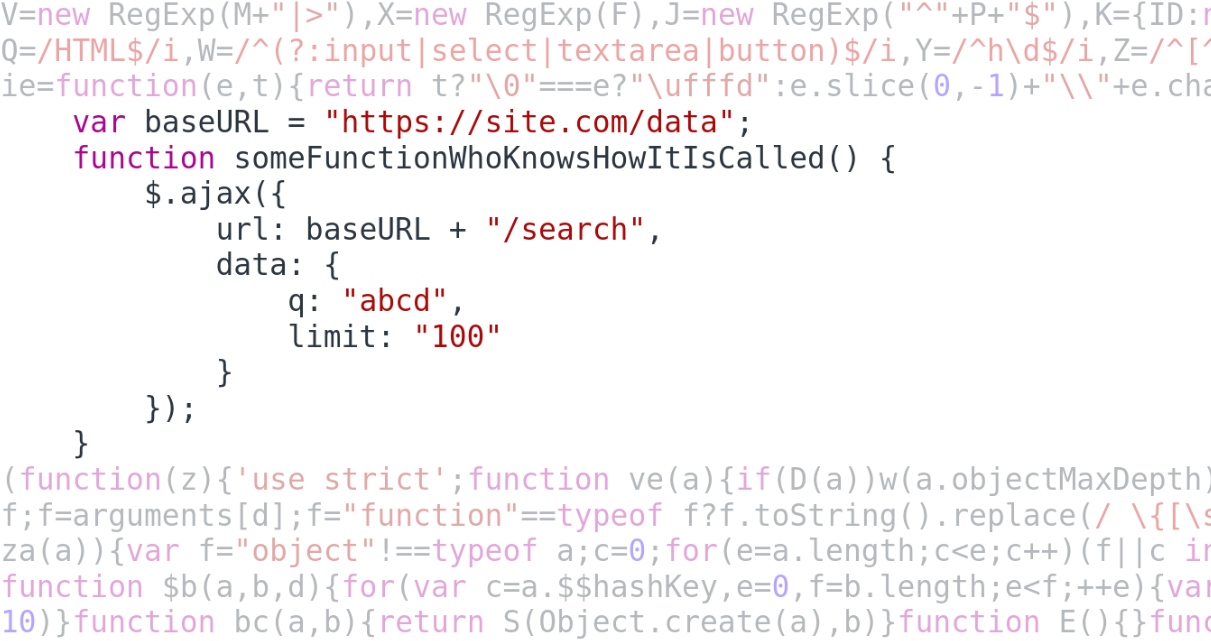
We see with our eyes what request is sent from the function in this code — there should be a way to find that automatically, right?
And we thought: a great deal of websites send requests to server from client-side JS and client-side JS of any site is available — so our analysis should be usable with a whole lot of sites, potentially finding new server endpoints — and therefore increasing the chances of finding a vulnerability. Sounds cool!
Existing analyzers
JavaScript is extremely widely used, it has long been the main and de-facto the only language to implement the web app’s client side. So for sure, there should already be some static analyzers for JS, right? Maybe we could use one of them?
It turns out things are not that easy. Yes, there are some static analyzers for JS, we found quite a few of them. But they didn’t help much. The fact is that JS is a language that’s very hard to analyze statically. There are several static analyzers for JS well known in academic literature (for example TAJS, SAFE, WALA) — but they all often have problems when analyzing real web pages. On pages with non-trivial JS, it is not infrequent for these analyzers to hang forever or crash with an error. This happens even on the page, where the only piece of JS code is the jQuery library (and jQuery is present on 77% of websites). With non-scientific tools the situation is similar: they either crash on real-world JS code or give too little information about the code.
The common choice for security-oriented analyzers for JavaScript is to use dynamic analysis. Which makes sense — apart from the fact that static analysis is intimidatingly complex, searching for vulnerabilities in the code we are unable to trigger does not seem to be all that interesting (if the vulnerable code is not executed, how do we exploit the vulnerability?).
All this meant that, if we wanted to get a tool that works on real applications, we had to write our own, new static analyzer. But is that even possible? After all, the existing analyzers had little success. And, if that is possible — then how?
How
How do we statically analyze the JavaScript code of the web pages? Well, to start with, we would have to get
that code. Suppose we have a web page’s URL — how do we gather all its JS? There are several ways to do that,
for our analyzer we’ve chosen to use the headless browser and its debugger. Using the real browser is a way
to get a real environment, where web pages are rendered and JS code is executed — so, we have fewer chances to
get problems caused by discrepancies in parsing nuances or web standard implementations (and there are tons of such nuances).
Moreover, using the debugger we can get all JS code executed on the page regardless of how it was executed — was
it present inline in the web page’s markup, loaded from a URL, or created dynamically and executed using the function eval or
Function. We will also know the order of script execution — we will get the scripts from the debugger in the same order
they were passed to JS interpreter. Let’s see how this all can be implemented using, for example, Headless Chrome.
We will be using the puppeteer JS library. It can be installed using npm:
npm install puppeteer
First of all, we have to open the page with the URL we want:
const puppeteer = require('puppeteer');
const url = 'https://www.solidpoint.net/';
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
console.log(`loaded page, url: ${page.url()}, title: ${await page.title()}`);
await browser.close();
})();
Okay, we know how to load the page, now we want to get the scripts that are executed on it — for that, we will use the
Debugger API. puppeteer does not by
itself provide the methods to use this API, so we will have to “manually” send the needed Chrome DevTools Protocol (CDP) messages.
For that, we will ask the library to provide us with a client object for the CDP protocol:
// ...
(async () => {
// ...
const page = await browser.newPage();
const client = await page.createCDPSession();
// ...
})
We can now send the CDP messages using this client and get responses to them (using await client.send(...)) and also subscribe to events
coming from the browser (using client.on(...)). We will subscribe to the event Debugger.scriptParsed
so that we are notified about the appearance of new scripts. We will then use the method Debugger.getScriptSource
in order to get the code of those scripts as they appear.
// ...
(async () => {
// ...
const client = await page.createCDPSession();
// we will gather the scripts from the page in this array
const pageScripts = [];
await client.send('Debugger.enable'); // enable the debugger for this page
client.on('Debugger.scriptParsed', async function ({ scriptId, url }) {
const { scriptSource } = await client.send(
'Debugger.getScriptSource', { scriptId }
);
pageScripts.push({ scriptSource, url });
});
// we have prepared script gathering - now open the URL!
await page.goto(url);
console.log(pageScripts); // let's print what was gathered there
// ...
})();
Our program now gathers the source code of JS scripts that get into the JS engine while the page is loading.
Alright, we have the code now, but how do we analyze it? Firstly, we should transform the code from the text form into something more machine-readable. In other words, parse it. There are many parsers for JS, here are a couple of well-known ones: esprima, @babel/parser (it used to be called Babylon, by the way).
They can be installed with npm, just like puppeteer. For @babel/parser the command would be:
npm install @babel/parser
JS can be parsed with @babel/parser using the following code:
const babelParser = require('@babel/parser');
const code = 'y = k*x + 5';
const ast = babelParser.parse(code);
console.log(ast);
The parser outputs an abstract syntax tree (AST).
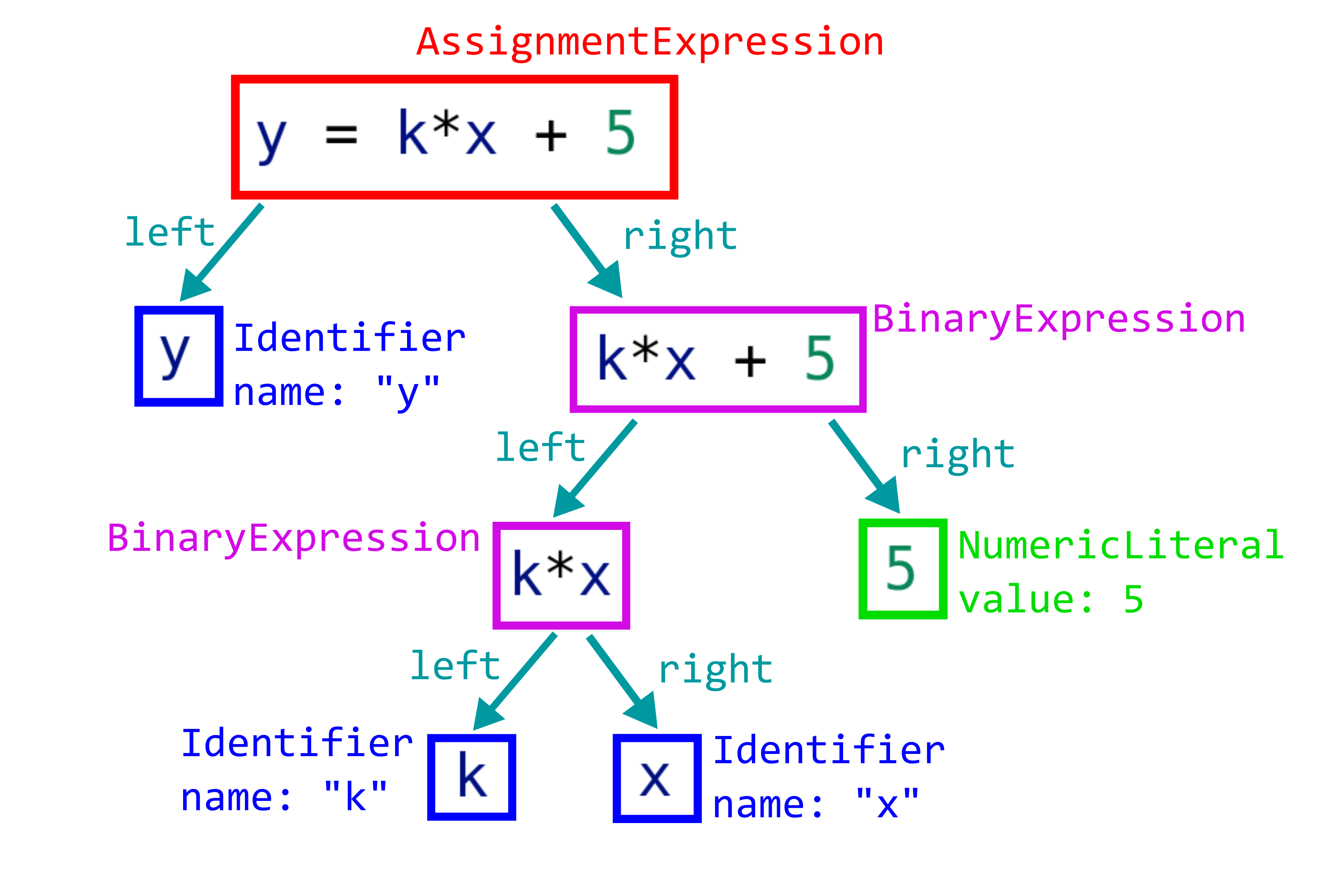
AST for code “y = k*x + 5”
Okay, so we have an AST, but how do we search for HTTP requests sent to a server? As my first team lead
in the world of development taught me, let’s start with something as simple as possible.
We know that requests are sent from the code using the API function/method calls. Let us choose
a single target to start with, function fetch() for instance. And search for its calls.
To search through the entire code, we can recursively traverse the whole AST. There are libraries for that too,
in case of Babel @babel/traverse is such a library (it can also be installed using npm). This library
provides a function traverse that accepts an AST and an object containing the callbacks.
We can traverse the code looking for fetch calls like this:
const babelParser = require('@babel/parser');
const { default: traverse } = require('@babel/traverse');
const fs = require('fs');
const code = fs.readFileSync('sample.js', 'utf8');
const ast = babelParser.parse(code);
traverse(ast, {
enter: function(path) {
const node = path.node;
if (node.type === 'CallExpression') {
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
console.log('fetch found!');
}
}
}
});
The callback enter is called each time an AST node is entered during the tree traversal.
This means that function in the code above will be called for all AST nodes — and
we are performing checks to detect the node we’re looking for. To be more precise,
we are interested in function calls — AST nodes with type CallExpression are
responsible for them. But we’re not interested in just any calls, we want the
ones where the function being called is given as an identifier fetch (AST node with the type Identifier).
By the way, the documentation with all types of AST nodes given by Babel can be
found here.
And it’s convenient to examine the AST structure in AST explorer.
We can try to run the code we’ve just written on the following sample (saved to sample.js):
function f(someCondition) {
if (someCondition) {
fetch('/api/send-data.action?mode=1', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
},
body: 'data=abc123',
});
}
}
The code should print fetch found!.
Well, our code has found this call, but we would like it to output its arguments — the data
passed into the call — so that we can understand what request is being sent. For that we’ll have
to improve our code, make it examine the call arguments. Information about them is
stored in .arguments field of the CallExpression node. To convert the arguments
from AST nodes into the readable code we can use the @babel/generator library —
it can transform AST nodes back into the source code. We can also make our code
shorter by changing the name of the callback we pass to Babel — instead of using the enter
callback, let’s name it CallExpression — for such a callback traverse will by
itself check the type of the AST node and our callback will be only called for
nodes with type CallExpression. So we won’t need the node.type === 'CallExpression' check.
The code will then look like this:
const babelParser = require('@babel/parser');
const { default: traverse } = require('@babel/traverse');
const { default: generate } = require('@babel/generator');
const fs = require('fs');
const code = fs.readFileSync('sample.js', 'utf8');
const ast = babelParser.parse(code);
traverse(ast, {
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
args.push(generate(argNode).code);
}
console.log(`fetch(${args.join(',')})`);
}
}
});
When run on our sample this code will output the following:
fetch('/api/send-data.action?mode=1',{
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
},
body: 'data=abc123'
})
This worked, and such an output is already useful. But this is not super interesting. What if the URL was not given by a string, but by a variable?
Variables
What if we had the following code:
function f(someCondition) {
var url = '/api/get-data.action?mode=1';
if (someCondition) {
fetch(url);
}
}
Our program then won’t print the real value of the first argument, instead, it will print
the variable name url. Which isn’t very useful. So let’s try to implement variable support!
We can store variables in a dictionary (Map). We can use the variable name as the key in the dictionary (and the variable value will become the value corresponding to this key). When seeing variables being declared (VariableDeclarator nodes) we will put them into the dictionary, and when we meet
variable usages we’ll read them from it. Let’s start with variables that are initialized by a string literal. Our AST traversal
will then look like this:
const memory = new Map(); // variables
traverse(ast, {
VariableDeclarator: function(path) {
const { id, init } = path.node;
if (init && id.type === 'Identifier' && init.type === 'StringLiteral') {
memory.set(id.name, init.value);
}
},
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
if (argNode.type === "Identifier") {
const value = memory.get(argNode.name);
args.push(JSON.stringify(value)); // JSON.stringify to add quotes
} else {
// dunno what to do with this node: just convert to source
args.push(generate(argNode).code);
}
}
console.log(`fetch(${args.join(',')})`);
}
}
});
This code handles the most simple string variables. But often URL value is computed in a more complex way.
Expressions
A variable holding a URL can be re-assigned, it can be assigned a result of some expression over other pieces of data. The following example is quite common:
function f(someCondition) {
var url = '';
var baseURL = '/api',
mode = '1';
if (someCondition) {
url = baseURL + '/send-data.action';
fetch(url + '?mode=' + mode);
}
}
To support such cases, it will be convenient for us to define a separate function for evaluating expressions. It will also be useful to have a special unique value for cases when the value is unknown, we could not determine it.
const UNKNOWN_VALUE = { toString: function() { return '{???}'; } }
function evalExpr(node) {
switch(node.type) {
case 'StringLiteral':
return node.value;
case 'Identifier':
if (memory.has(node.name)) {
return memory.get(node.name);
}
break;
case 'BinaryExpression':
if (node.operator === '+') {
return evalExpr(node.left) + evalExpr(node.right);
}
break;
}
// we've done the best we could
return UNKNOWN_VALUE;
}
Setting a value of a variable also deserves a separate function because it can happen
in different places — when initializing a variable or when assigning a value to it (AssignmentExpression).
function setVariable(varNode, valueNode) {
if (varNode.type === 'Identifier') {
memory.set(varNode.name, evalExpr(valueNode));
}
}
Our tiny algorithm will then look like this:
traverse(ast, {
VariableDeclarator: function(path) {
if (path.node.init) {
setVariable(path.node.id, path.node.init);
}
},
// process assignments, not only initializations
AssignmentExpression: function(path) {
if (path.node.operator === '=') {
setVariable(path.node.left, path.node.right);
}
},
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
const value = evalExpr(argNode);
if (value !== UNKNOWN_VALUE) {
args.push(JSON.stringify(value));
} else {
args.push(generate(argNode).code);
}
}
console.log(`fetch(${args.join(',')})`);
}
}
});
Scopes
The program we’ve just written identifies the variables simply using their names (which are strings basically). But in JS there can be several different variables with identical names in different scopes. Our analyzer will confuse them with each other at the moment. This can be a problem, especially if there are many single-lettered, non-unique variable names in the program. In real client-side code, this happens all the time due to minification: all variables get renamed so that their names are as short as possible. The problem would arise, for example, with the following code:
function f(someCondition) {
var u = '';
var b = '/api',
m = '1';
if (someCondition) {
u = b + '/get-data.action';
var errCb = function(err) {
var u, m;
u = 'at url addr ' + location.href;
m = 'msg ' + err.message;
console.error(`Page ${u}: got error ${m}`);
}
fetch(u + '?mode=' + m).catch(errCb);
}
}
There is a separate scope inside the nested function errCb, and variables defined
there are different from the outer ones — but our analyzer won’t currently understand
that. To fix this, we have to find a way to distinguish variables from different
scopes. To achieve that, we could rename the variables in the program so that
all variables would have unique names (change the analyzed code a little bit) —
this is often done in practice. Another option is to use something different as a
key in our map for variables. Some special values, that would correspond 1-to-1 to each
variable, uniquely identifying them (even those having the same name). Thankfully,
the Babel library already provides us with this: in addition to creating an AST,
it figures out what scopes are present in the program and gives this information to
the user. For each scope Babel creates an instance of the
Scope class
and for each variable there is an instance of class Binding. Scope containing the current node can be obtained
from the path.scope property. To get a Binding the Scope’s method .getBinding(name) can be used.
Thus, setting the variable’s value can be updated to look like this:
function setVariable(varNode, valueNode, scope) {
if (varNode.type === 'Identifier') {
const binding = scope.getBinding(varNode.name);
memory.set(binding, evalExpr(valueNode, scope));
}
}
And expression evaluation, that can get variable values from memory, can be updated like this:
function evalExpr(node, scope) {
switch(node.type) {
case 'StringLiteral':
return node.value;
case 'Identifier':
const binding = scope.getBinding(node.name);
if (memory.has(binding)) {
return memory.get(binding);
}
break;
case 'BinaryExpression':
if (node.operator === '+') {
return evalExpr(node.left, scope) + evalExpr(node.right, scope);
}
break;
}
// giving up
return UNKNOWN_VALUE;
}
Accordingly, when processing the AST nodes we now have to pass those scope objects
into the updated functions:
traverse(ast, {
VariableDeclarator: function(path) {
if (path.node.init) {
setVariable(path.node.id, path.node.init, path.scope);
}
},
// process assignments, not only initializations
AssignmentExpression: function(path) {
if (path.node.operator === '=') {
setVariable(path.node.left, path.node.right, path.scope);
}
},
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
const value = evalExpr(argNode, path.scope);
if (value !== UNKNOWN_VALUE) {
args.push(JSON.stringify(value));
} else {
args.push(generate(argNode).code);
}
}
console.log(`fetch(${args.join(',')})`);
}
}
});
Now, keys in our memory are variable bindings and variables with the same name
will be distinguished.
Let’s also add support for function $.ajax — having only one supported function
for sending requests is not cool. To make the code shorter, we will be using
the helper functions from @babel/types:
/* ... */
const { isIdentifier, isMemberExpression } = require('@babel/types');
/* ... */
traverse(ast, {
/* ... */
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
let ajaxFunction = null;
if (isIdentifier(callee, { name: 'fetch' })) {
ajaxFunction = 'fetch';
} else if (
isMemberExpression(callee) && isIdentifier(callee.object, { name: '$'}) &&
isIdentifier(callee.property, { name: 'ajax'})
) {
ajaxFunction = '$.ajax';
}
if (ajaxFunction) {
const args = [];
for (const argNode of node.arguments) {
const value = evalExpr(argNode, path.scope);
if (value !== UNKNOWN_VALUE) {
args.push(JSON.stringify(value));
} else {
args.push(generate(argNode).code);
}
}
console.log(`${ajaxFunction}(${args.join(',')})`);
}
}
});
— So, was that static analysis just now? — you might ask. Actually, yes, and a nontrivial one. Even linters are considered static analyzers, although they consider only the syntax of the language — and we even take some semantics into account! Сertainly, this analyzer is naive, it misses a lot of things. If you are interested in static analysis and want to learn how it can be done, I recommend this (more serious) talk about it from the fabulous Matt Might (video, same as a blog post). The sound in Matt Might’s lecture video is not perfect, but still, the lecture is very good. Several more links will be given at the end of this post. Nevertheless, our tiny analysis already works and will find some calls that send requests to server. Try to use it on some pages! If you don’t know which page to pick, you can try to run it on, for example, promote.telegram.org or on this page, that belongs to our lab’s site. The algorithm we’ve written can be easily extended to support other names of AJAX functions or to support object literals, so that expression evaluation and variable substitution also work inside objects. This repo contains the full final version of the code of the mini-analyzer described above, integrated with the part that gathers the page’s scripts.
Our algorithm
Okay, a simple, educational JS analysis algorithm was described above. But how does the real analysis algorithm developed in our lab work? The one I promised to tell you about.
The thing is, on a conceptual level, it works roughly the same way. The algorithm
performs a recursive depth-first AST traversal, for variable assignments (and initializations)
it memorizes the assigned values. It also has a special unknown value, which is simply called UNKNOWN.
It has the same memory map, where keys are Binding objects. There is no special handling of for loops:
when traversing the AST, the algorithm will enter the loop body just like any other node — so,
loops are analyzed as if they all made a single iteration. Calls that send requests to server are
detected in the same way: using the function name (or object name + method name).
When meeting such a call during an AST traversal, the algorithm tries to evaluate the values of
the arguments given to that call — and computed argument values together with the function name are added
to the result array. The JS code is also gathered using the headless browser and its debugger.
But, still, there are many details left, for example:
- A single AST traversal is actually not enough, several ones are made.
- How do we handle data passed between functions? How do we determine what values come from function arguments?
- What do we do with the
XMLHttpRequestclass — it does not have a single point where all data is given at once, instead, different parts of the request are set using different calls of its methods. - Ideally, rather than getting the names of called functions with sets of argument values, we would like to get HTTP requests themselves — how do we achieve this?
Don’t miss out on the following posts, where I’ll tell about these and some other details of our algorithm, the results of its work, some conclusions we’ve made and the source code release of our actual analyzer. The posts are out already — here is the first one, and here is the second!
(If you’re eager to get the source code link, it’s here)
References
If you wish to learn more about static analysis, I highly recommend this:
- Matt Might — “What is Static Analysis?” — video, same as a blog post (actually, there is a bit more in the blog post than in the video)
- Book: Anders Møller, Michael I. Schwartzbach — “Static Program Analysis”
- Course: Michael Pradel — Program Analysis at University of Stuttgart