Майнинг HTTP-запросов из клиентского JS с помощью статического анализа
Привет! Мы в лаборатории компьютерной безопасности на факультете ВМК МГУ уже какое-то время занимаемся анализом клиентского JavaScript-кода для обнаружения HTTP-запросов, которые из него могут отправляться на сервер (AJAX-запросов). Цель — передать эту информацию сканеру, который ищет веб-уязвимости на стороне сервера в «black-box» режиме (когда нет доступа к серверным исходникам). Чтобы сканер знал, какие запросы принимает сервер, а значит, в какие запросы можно подставлять атакующие вектора. И мы сами делаем сканер веб-уязвимостей SolidPoint, в котором этот анализ используется. В этом посте и нескольких следующих расскажу про этот анализ: почему мы стали его делать, как он работает, что получается в результате.
Кстати, мы писали про это научные статьи (вот первая и основная из них), ещё я делал про это доклад в 2022 году (видео, слайды и другие материалы). Здесь будет примерно то же самое что и там, но написанное в блог-постовом формате.
Почему
Почему мы решили этим заняться? Ещё давным-давно во время пентестов мы периодически находили в клиентском JS отправку запросов к серверным ручкам, которые из интерфейса не задействовались. Бывало, что среди JS-кода на странице был код, соответствующий страницам админки, бывало такое, что вообще весь клиентский код сайта бандлился вместе и присутствовал на странице. Иногда в проверке аутентификации на сервере бывали ошибки (её могли просто забыть сделать) и тогда, найдя запрос в JS, мы могли совершить действие, которое текущему пользователю не должно было быть доступно (в том числе такое бывало и с админкой). Мы читали клиентский код и понимали, что за запрос отправляется. Так может быть, подумали мы, это можно делать как-то автоматически?
Запросы, отправляемые элементами HTML-разметки, найти несложно, а вот с JS труднее. Чтобы находить, какие запросы отправляет клиентский JS, сканеры обычно используют динамический краулинг — взаимодействие со страницами сайта с помощью управляемого браузера (headless браузера, например Headless Chrome). Это неплохо работает, но этот метод точно не найдёт такие запросы, как хотели находить мы — ведь для них нет элементов интерфейса, есть только JS-код, который был оставлен ненамеренно. Кроме того, даже с действиями, которые из интерфейса вызвать можно, у динамического краулера бывают проблемы — бывает что интерфейс страницы сложный, такой, в котором возможно много действий. А какие комбинации из этих действий приведут к отправке запроса краулер не знает. Чтобы найти запрос, который отправится после длинной цепочки действий, краулеру может потребоваться перепробовать слишком много всего, это может занять вечность. Поэтому мы решили попробовать сделать штуку, которая бы извлекала отправляемые запросы, не взаимодействуя с интерфейсом, а непосредственно из самого кода. То есть анализатор JavaScript-кода. Мы решили, что начать надо со статического анализа — ведь статический анализ умеет покрывать весь код вообще, независимо от того, насколько сложно его достичь при реальном выполнении.
Мы видим глазами, какой запрос отправляет функция в этом коде — должно же быть можно как-то автоматически это найти?
Ну и мы подумали: ведь куча сайтов отправляет с помощью клиентского JS запросы, при этом клиентский JS любого сайта доступен — значит, наш анализ можно применить к очень многим сайтам, потенциально найдя запросы к новым серверным ручкам — а значит, повысив вероятность найти уязвимость. Звучит прикольно!
Существующие анализаторы
JavaScript очень распространён, он уже давно главный и де-факто единственный язык для клиентской части сайтов — наверняка уже существуют какие-то статические анализаторы JS, верно? Может, можно использовать какой-то из них?
Выяснилось, что не совсем. Да, статические анализаторы JS вроде бы и есть, даже немало, но они мало что могут. Потому что JS вообще-то очень тяжело анализировать статически. Существуют несколько известных в научных статьях статических анализаторов (например TAJS, SAFE, WALA) — но все они неспособны анализировать реальные страницы современных сайтов, на любой странице с хоть сколько-нибудь нетривиальным кодом они либо зависают навсегда, либо падают с ошибкой. Либо и то и то (зависают на очень долго и потом падают с ошибкой). Такое происходит даже на простейшей страничке, где есть только библиотека jQuery (при этом jQuery сейчас есть на 77% сайтов). С тулзами не из научных статей ситуация похожая: они либо ломаются на реальном коде, либо дают о нём слишком мало информации.
Вообще, security-ориентированные анализаторы клиентского JS часто используют динамический анализ. Что можно понять — кроме того, что статанализ отпугивает своей сложностью, искать уязвимости в коде, который не получается стриггерить, как будто не так интересно (если уязвимый код не выполняется, то как эксплуатировать уязвимость)?
Это всё означало, что, если мы хотели получить тулзу, которая работает на реальных приложениях, нам нужно было написать свой, новый статический анализатор. А это вообще возможно? Ведь у существующих анализаторов не получилось. И если возможно — то как?
Как
Так как же статически анализировать JavaScript-код веб-страниц? Ну, для начала нам надо получить его. Вот у нас есть URL веб-страницы, как собрать с неё весь JS? Есть несколько способов это сделать, мы в нашем анализаторе выбрали использовать управляемый браузер и его дебаггер. Управляемый браузер ближе всего к реальной среде, в которой рендерятся страницы и выполняется JS (по сути, браузер это и есть реальная среда) — соответственно, у нас меньше шансов получить проблемы из-за расхождений в нюансах парсинга и реализации стандартов веба (а этих нюансов великое множество). Кроме того, с помощью дебаггера мы можем получить любой JS-код, выполненный на странице, откуда бы он ни взялся — был ли он в коде страницы, был ли он загружен по URL, был ли он как-то сложно динамически сформирован и выполнен с помощью eval или Function. Также мы будем знать порядок скриптов — получим их в том же порядке, в котором они в реальности попадали в интерпретатор JS. Давайте посмотрим, как это можно реализовать на примере Headless Chrome. Для этого используем JS-библиотеку puppeteer. Её можно поставить через npm:
npm install puppeteer
Для начала нам надо открыть страницу с нужным URL:
const puppeteer = require('puppeteer');
const url = 'https://www.solidpoint.net/';
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
console.log(`loaded page, url: ${page.url()}, title: ${await page.title()}`);
await browser.close();
})();
Грузить страницу умеем, теперь мы хотим получить выполняемые на ней скрипты — для этого используем Debugger API. Библиотека puppeteer сама по себе не предоставляет методов для работы с этим API, поэтому нам нужно будет вызывать отправку сообщений Chrome DevTools Protocol (CDP) «вручную». Для этого нам надо попросить библиотеку предоставить нам объект-клиент для общения по протоколу CDP:
// ...
(async () => {
// ...
const page = await browser.newPage();
const client = await page.target().createCDPSession();
// ...
})
Теперь с помощью этого клиента мы можем отправлять CDP-сообщения и получать на них ответы (с помощью await client.send(...)) и подписываться на события, приходящие от браузера (с помощью client.on(...)). Мы подпишемся на событие Debugger.scriptParsed, чтобы нас оповещали о появлении новых скриптов, и используем метод Debugger.getScriptSource, чтобы получать их код.
// ...
(async () => {
// ...
const client = await page.target().createCDPSession();
// в этот массив будем собирать скрипты со страницы
const pageScripts = [];
await client.send('Debugger.enable'); // включим дебаггер для этой страницы
client.on('Debugger.scriptParsed', async function ({ scriptId, url }) {
const { scriptSource } = await client.send(
'Debugger.getScriptSource', { scriptId }
);
pageScripts.push({ scriptSource, url });
});
// мы подготовили сбор скриптов - теперь откроем URL!
await page.goto(url);
console.log(pageScripts); // напечатаем что там собралось
// ...
})();
Теперь наша программа собирает JS-код скриптов, попадающих в интерпретатор во время загрузки страницы.
Что ж, код мы получили, но как его анализировать? Прежде всего, надо преобразовать код из текстового формата в формат, который удобнее обрабатывать программно. Распарсить его. Существует много парсеров JS-кода, вот пара известных примеров: esprima, @babel/parser (раньше он, кстати, красиво назывался Babylon).
Установить их можно, как и puppeteer, с помощью npm. В случае @babel/parser это будет такая команда:
npm install @babel/parser
Распарсить JS с помощью @babel/parser можно вот таким кодом:
const babelParser = require('@babel/parser');
const code = 'y = k*x + 5';
const ast = babelParser.parse(code);
console.log(ast);
Парсер выдаёт абстрактное синтаксическое дерево (abstract syntax tree, обычно его называют сокращённо AST).
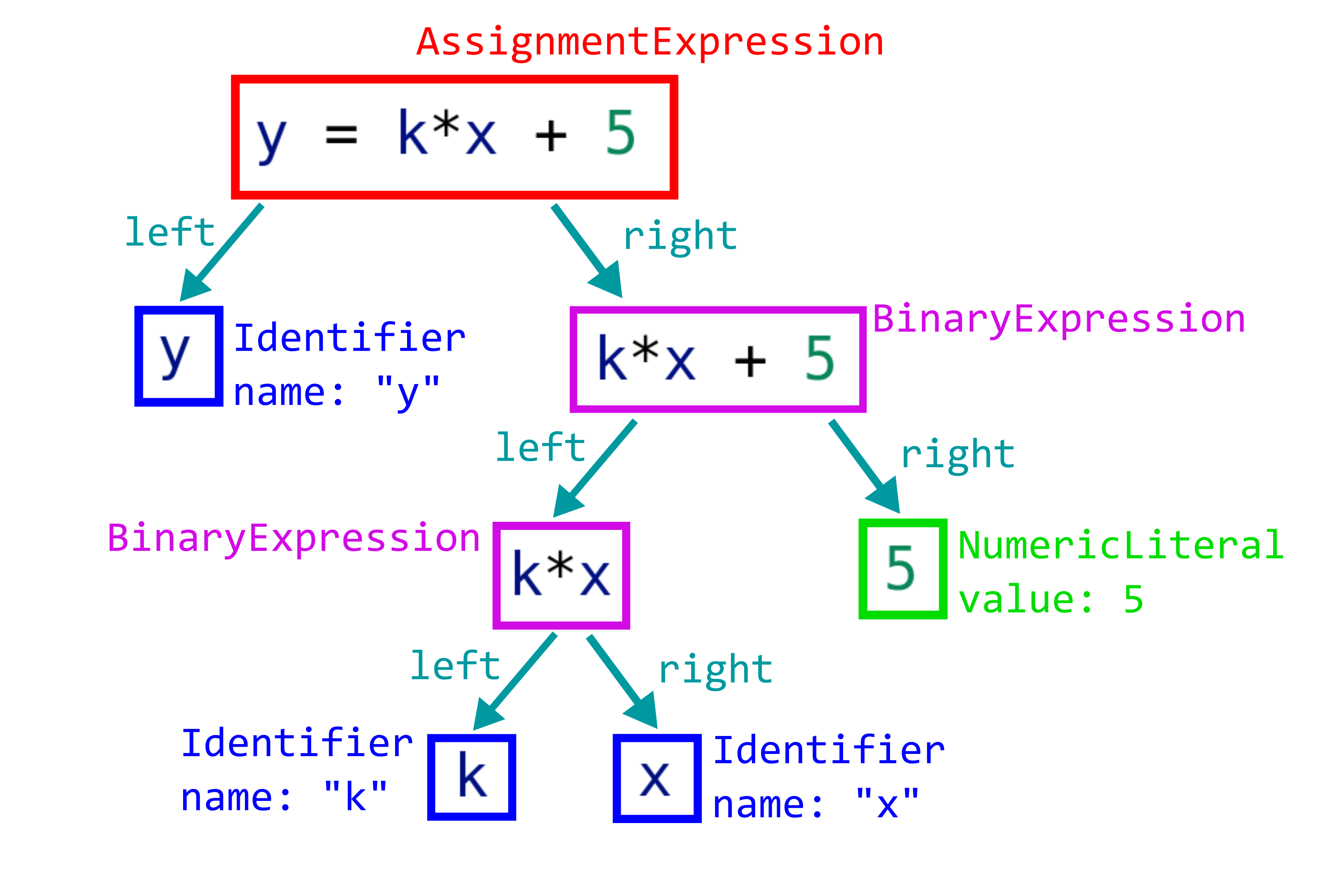
AST-дерево для кода «y = k*x + 5»
Окей, вот у нас есть AST-дерево, как нам искать отправляемые на сервер запросы? Как учил меня мой первый тимлид в мире разработки, давайте начнём с чего-то максимально простого. Мы знаем, что запросы в коде чаще всего отправляются вызовами API-функций/методов, начнём с какого-то одного таргета, пусть это будет функция fetch(). Поищем в коде вызовы этого fetch(). Чтобы сделать поиск по всему коду можно рекурсивно обойти всё AST-дерево. Для этого тоже есть готовые библиотеки, в случае Babel это будет @babel/traverse (также ставится через npm). Эта либа предоставляет функцию traverse, которая принимает AST и объект с колбеками. Обойти код в поисках fetch можно с помощью этой либы так:
const babelParser = require('@babel/parser');
const { default: traverse } = require('@babel/traverse');
const fs = require('fs');
const code = fs.readFileSync('sample.js', 'utf8');
const ast = babelParser.parse(code);
traverse(ast, {
enter: function(path) {
const node = path.node;
if (node.type === 'CallExpression') {
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
console.log('fetch found!');
}
}
}
});
Колбек с именем enter вызывается при входе в каждую AST-ноду при обходе дерева. То есть функция в этом коде будет вызвана для вообще всех вершин AST — и мы делаем проверки чтобы опознать интересующую нас. Точнее, нас интересуют вызовы функций - за них отвечает AST-нода типа CallExpression. Далее, мы хотели бы находить не все вызовы вообще, а те, которые выглядят как вызовы функции, данной как идентификатор fetch (AST-вершина c типом Identifier). Кстати, доку по всем видам вершин AST-дерева, которое выдаёт Babel, можно найти тут. А смотреть как выглядит AST-дерево какого-то кода удобно в AST explorer.
Можно попробовать запустить этот код на каком-то таком примере (сохранив пример в sample.js):
function f(someCondition) {
if (someCondition) {
fetch('/api/send-data.action?mode=1', {
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
},
body: 'data=abc123',
});
}
}
Код должен выдать fetch found!
Ну хорошо, он нашёл этот вызов, но нам бы хотелось, чтобы он выдавал ещё и его аргументы — данные, которые в него передаются — чтобы понимать, что там отправляется. Для этого код надо будет доработать, чтобы он смотрел на аргументы вызова. Информация о них записана у CallExpression-ноды в поле .arguments. Чтобы аргументы превратить из AST-нод в удобный для чтения код, можно использовать библиотеку @babel/generator — она умеет превращать AST-вершины обратно в код. Ещё, кстати, код можно сделать покороче на счёт использования колбека с именем не enter, а CallExpression — для него traverse будет сам делать проверку типа ноды и вызывать наш колбек только для нод CallExpression. И проверка node.type === 'CallExpression' будет не нужна. Тогда код может принять такой вид:
const babelParser = require('@babel/parser');
const { default: traverse } = require('@babel/traverse');
const { default: generate } = require('@babel/generator');
const fs = require('fs');
const code = fs.readFileSync('sample.js', 'utf8');
const ast = babelParser.parse(code);
traverse(ast, {
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
args.push(generate(argNode).code);
}
console.log(`fetch(${args.join(',')})`);
}
}
});
При запуске на нашем примере выше он теперь выдаст
fetch('/api/send-data.action?mode=1',{
method: 'POST',
headers: {
'Content-Type': 'application/x-www-form-urlencoded'
},
body: 'data=abc123'
})
Это сработало, такой вывод уже может быть полезен. Но всё-таки это не очень интересно. Что если бы URL был задан не прямо строкой в аргументах, а переменной?
Переменные
Что если бы код был каким то таким:
function f(someCondition) {
var url = '/api/get-data.action?mode=1';
if (someCondition) {
fetch(url);
}
}
Тогда наша программа выдаст на месте первого аргумента не реальное значение, а имя переменной url. Что не очень полезно. Так давайте попробуем добавить поддержку переменных!
Мы можем завести под переменные словарь (Map), куда будем сохранять все переменные, что мы видели. Ключом может быть имя переменной, значением — её значение. При виде объявлений переменных (VariableDeclarator) будем запоминать их в словаре, при использовании - доставать оттуда. Начнём с переменных, инициализированных строковым литералом. Тогда наш обход AST изменится вот так:
const memory = new Map(); // variables
traverse(ast, {
VariableDeclarator: function(path) {
const { id, init } = path.node;
if (init && id.type === 'Identifier' && init.type === 'StringLiteral') {
memory.set(id.name, init.value);
}
},
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
if (argNode.type === "Identifier") {
const value = memory.get(argNode.name);
args.push(JSON.stringify(value)); // JSON.stringify to add quotes
} else {
// dunno what to do with this node: just convert to source
args.push(generate(argNode).code);
}
}
console.log(`fetch(${args.join(',')})`);
}
}
});
Этот код справляется с самыми простыми строковыми переменными. Но ведь URL нередко задаётся сложнее.
Выражения
Переменная с URL-адресом может где-то переприсваиваться, задаваться как какое-то выражение от других данных, то есть вполне может быть что-то такое:
function f(someCondition) {
var url = '';
var baseURL = '/api',
mode = '1';
if (someCondition) {
url = baseURL + '/send-data.action';
fetch(url + '?mode=' + mode);
}
}
Чтобы поддерживать такие случаи, нам будет удобнее ввести уже отдельную функцию вычисления выражений. Также будет полезно завести специальное уникальное значение для случаев, когда значение неизвестно, найти его не удалось.
const UNKNOWN_VALUE = { toString: function() { return '{???}'; } }
function evalExpr(node) {
switch(node.type) {
case 'StringLiteral':
return node.value;
case 'Identifier':
if (memory.has(node.name)) {
return memory.get(node.name);
}
break;
case 'BinaryExpression':
if (node.operator === '+') {
return evalExpr(node.left) + evalExpr(node.right);
}
break;
}
// тут наши полномочия всё (окончены)
return UNKNOWN_VALUE;
}
Для задания значения переменной тоже стоит завести отдельную функцию, потому что оно может происходить из нескольких мест — из инициализации при объявлении и при присвоении (AssignmentExpression).
function setVariable(varNode, valueNode) {
if (varNode.type === 'Identifier') {
memory.set(varNode.name, evalExpr(valueNode));
}
}
Тогда наш маленький алгоритм анализа может принять такой вид:
traverse(ast, {
VariableDeclarator: function(path) {
if (path.node.init) {
setVariable(path.node.id, path.node.init);
}
},
// process assignments, not only initializations
AssignmentExpression: function(path) {
if (path.node.operator === '=') {
setVariable(path.node.left, path.node.right);
}
},
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
const value = evalExpr(argNode);
if (value !== UNKNOWN_VALUE) {
args.push(JSON.stringify(value));
} else {
args.push(generate(argNode).code);
}
}
console.log(`fetch(${args.join(',')})`);
}
}
});
Области видимости
Программа, которую мы сейчас написали, идентифицирует переменные просто по их именам (то есть строкам). Но в JavaScript может быть несколько разных переменных с одинаковыми именами — в разных областях видимости. Наш анализатор сейчас будет их путать. Это может стать проблемой, особенно если в программе много однобуквенных, неуникальных имён. В реальном клиентском коде такое происходит постоянно из-за минификации: имена всех переменных меняются на максимально короткие. Проблема возникла бы, например, в таком коде:
function f(someCondition) {
var u = '';
var b = '/api',
m = '1';
if (someCondition) {
u = b + '/get-data.action';
var errCb = function(err) {
var u, m;
u = 'at url addr ' + location.href;
m = 'msg ' + err.message;
console.error(`Page ${u}: got error ${m}`);
}
fetch(u + '?mode=' + m).catch(errCb);
}
}
Внутри вложенной функции errCb уже другая область видимости, и переменные там другие — но наш анализ этого не поймёт. Чтобы это исправить, нам хорошо было бы различать одноимённые переменные из разных скоупов. Для этого можно было бы переименовать переменные в программе так, чтобы все переменные имели уникальные имена (то есть преобразовать немного анализируемый код) — так нередко делают на практике. Ещё один вариант — вместо просто имени переменной использовать в качестве ключа в memory какие-то специальные значения, которые бы переменным однозначно соответствовали (были бы разными для разных переменных). К счастью, библиотека Babel уже предоставляет нам это: помимо просто AST-дерева, она разбирается какие в программе есть области видимости — и предоставляет эту инфу. Для каждой области видимости Babel создаёт объект класса Scope, а для каждой переменной — объект класса Binding. Scope, в котором находится текущая нода, можно получить из свойства path.scope. Чтобы получить Binding можно использовать метод .getBinding(name), который есть у объектов класса Scope. Таким образом, задание переменной можно поменять вот так:
function setVariable(varNode, valueNode, scope) {
if (varNode.type === 'Identifier') {
const binding = scope.getBinding(varNode.name);
memory.set(binding, evalExpr(valueNode, scope));
}
}
А вычисление выражений, которое может доставать из memory значения переменных, так:
function evalExpr(node, scope) {
switch(node.type) {
case 'StringLiteral':
return node.value;
case 'Identifier':
const binding = scope.getBinding(node.name);
if (memory.has(binding)) {
return memory.get(binding);
}
break;
case 'BinaryExpression':
if (node.operator === '+') {
return evalExpr(node.left, scope) + evalExpr(node.right, scope);
}
break;
}
// тут наши полномочия всё (окончены)
return UNKNOWN_VALUE;
}
Ну и, соответственно, при обработке вершин AST эти объекты scope надо теперь в эти функции передавать:
traverse(ast, {
VariableDeclarator: function(path) {
if (path.node.init) {
setVariable(path.node.id, path.node.init, path.scope);
}
},
// process assignments, not only initializations
AssignmentExpression: function(path) {
if (path.node.operator === '=') {
setVariable(path.node.left, path.node.right, path.scope);
}
},
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
if (callee.type === 'Identifier' && callee.name === 'fetch') {
const args = [];
for (const argNode of node.arguments) {
const value = evalExpr(argNode, path.scope);
if (value !== UNKNOWN_VALUE) {
args.push(JSON.stringify(value));
} else {
args.push(generate(argNode).code);
}
}
console.log(`fetch(${args.join(',')})`);
}
}
});
Теперь ключами в нашем memory будут биндинги переменных, и одноимённые переменные будут различаться.
Ну и ещё добавим поддержку функции $.ajax — а то чего у нас один единственный fetch находится. Чтобы код был покороче, используем хелпер-функции из @babel/types:
/* ... */
const { isIdentifier, isMemberExpression } = require('@babel/types');
/* ... */
traverse(ast, {
/* ... */
CallExpression: function(path) {
const node = path.node;
const callee = node.callee;
let ajaxFunction = null;
if (isIdentifier(callee, { name: 'fetch' })) {
ajaxFunction = 'fetch';
} else if (
isMemberExpression(callee) && isIdentifier(callee.object, { name: '$'}) &&
isIdentifier(callee.property, { name: 'ajax'})
) {
ajaxFunction = '$.ajax';
}
if (ajaxFunction) {
const args = [];
for (const argNode of node.arguments) {
const value = evalExpr(argNode, path.scope);
if (value !== UNKNOWN_VALUE) {
args.push(JSON.stringify(value));
} else {
args.push(generate(argNode).code);
}
}
console.log(`${ajaxFunction}(${args.join(',')})`);
}
}
});
— И что, вот это сейчас статический анализ был? — спросите вы. Вообще-то да, и не самый тривиальный даже. К статическим анализаторам относят в том числе и линтеры, которые учитывают только синтаксис языка — а у нас тут даже немного учитывается семантика! Несомненно, этот анализатор наивный, он много чего не учитывает. Если вам интересен статический анализ и хочется получше узнать как его можно делать, я очень советую (более серьёзный) рассказ про него от потрясающего Мэтта Майта (видео, то же в виде блог-поста). В видео лекции Мэтта Майта неидеальный звук, но всё равно, она очень хороша. Ещё несколько ссылок (на учебные курсы и учебник) будут в конце поста. Тем не менее, наш маленький анализ уже работает и будет находить кое-какие вызовы даже сейчас. Попробуйте запустить его на какой-нибудь страничке! Если не знаете какую взять, то попробуйте, например, на promote.telegram.org или на вот этой страничке сайта нашей лаборатории. Этот алгоритм несложно доработать чтобы поддерживать другие имена AJAX-функций, добавить поддержку объектных литералов, чтобы внутри объектов тоже работало вычисление выражений и подстановка переменных. Вот в этом репозитории можно посмотреть полный финальный код описанного тут мини-анализатора, интегрированного той частью, которая собирает скрипты со страницы.
Наш алгоритм
Окей, выше был разобран простенький игровой алгоритм анализа JS для поиска вызовов, отправляющих запросы на сервер. Но как работает настоящий алгоритм анализа, который мы разработали в лаборатории, и про который я обещал рассказать?
А работает он на идейном уровне примерно так же. Алгоритм делает рекурсивный обход AST-дерева кода в глубину, для присваиваний (и инициализаций) переменных он запоминает, что было записано в качестве значения переменной. У него тоже есть специальное неизвестное значение, которое называется просто UNKNOWN. У него есть такая же вот мапа memory, ключом в которой являются объекты Binding. Нет никакой специальной обработки циклов: обходя AST, алгоритм заходит в тело цикла так же, как в другие вершины — то есть, циклы анализируются так, как будто они все делали по ровно одной итерации. Вызовы, отправляющие запросы на сервер, наш алгоритм опознаёт так же: с помощью имени функции (или имени объекта + имени метода). Наткнувшись на такой вызов при обходе AST, алгоритм пытается вычислить аргументы этого вызова — и вычисленные аргументы вместе с названием найденной функции добавляются в массив результатов анализа кода. Код он получает тоже с помощью управляемого браузера и его дебаггера. Но остаётся ещё немало подробностей, например:
- Одного обхода AST-дерева на самом деле недостаточно, их делается несколько.
- Как быть с передачей данных между функциями? Как определить данные, приходящие из аргументов функции?
- Как быть с классом
XMLHttpRequest— ведь у него нет единой точки, где в него передаются все данные, вместо этого разные части запроса задаются несколькими разными вызовами. - Мы хотели бы на выход получить всё таки не имена функций с аргументами, а HTTP-запросы — как быть с этим?
Про эти и кое-какие другие подробности нашего алгоритма, а также про то, какие получаются результаты его работы и какие выводы мы сделали, расскажу в следующих постах — вот первый из них, а вот второй!
Ссылки
Если вы хотите узнать больше про статический анализ, всячески рекомендую вот это:
- Matt Might — «What is Static Analysis?» — видео, то же в виде блог-поста (но на самом деле всё таки чуть больше)
- Учебник: Anders Møller, Michael I. Schwartzbach — «Static Program Analysis»
- Учебный курс Артура Хашаева «Анализ программ». Этот курс на русском языке
- Страница курса
- Чтобы получить доступ к видео лекций, надо написать Артуру Хашаеву на почту arthur@khashaev.ru или в telegram, его юзернейм это @inviz (для доступа к заданиям возможно тоже надо написать, но они могут быть и выложены на страничке курса)
- Учебный курс: Michael Pradel — Program Analysis at University of Stuttgart