Майнинг HTTP-запросов из клиентского JS с помощью статического анализа — часть 2
В предыдущем посте (гляньте его, если ещё не)
мы посмотрели на базовую идею работы алгоритма и даже построили небольшой анализатор, основанный на ней. В этом посте
расскажу ещё часть принципов устройства нашего алгоритма, включая поиск значений аргументов функций и хендлинг объектов типа инстансов XMLHttpRequest, а ещё кое-что про поддерживаемые операции.
И всё таки, как?
Как уже говорил, идейно алгоритм работает так же, как то, что было описано в прошлом посте. Но есть ряд отличий.
Поддерживаемые типы данных и операции
Анализатор поддерживает ряд типов данных, помимо строк и UNKNOWN. Среди них объекты, массивы, числа, boolean, ну и
undefined тоже (да-да, напомню, что для undefined в JavaScript есть отдельный тип). То есть для этих типов анализатор
превращает в значения их литералы (в том числе всякие [1, 2, 3] и {foo: "bar", abc: [true]}) и вычисляет результаты
некоторых операций с ними. В том числе чтение поля объекта/массива (a[x], ob.prop) и запись поля (a[x] = 123, ob.prop = v).
Также поддерживаются функциональные значения — для объявлений функций и функциональных выражений (литералов, если
угодно) анализатор тоже вырабатывает специальные значения, которые могут храниться в его memory.
То есть для вот такого кода
function f() {
return 123;
}
var g = function(x) {
return x * 25;
}
var k = f;
var l = g;
Анализатор поймёт, что переменные f и k указывают на первую функцию (которая возвращает 123), а g и l — на
вторую (которая возвращает свой аргумент, умноженный на 25).
Эти функциональные значения содержат в себе ссылку на код соответствующей функции (точнее, на её AST). Это пригодится для межпроцедурного анализа, про него расскажу дальше.
Кстати, можно заметить, что значения, про которые знает анализатор, могут не только непосредственно в memory быть
записаны — поскольку поддерживаются объекты и массивы, значения могут «сидеть» в полях объектов/массивов. Возможно, на
какой-то глубине (с несколькими уровнями вложенности).
Ещё анализатор умеет вычислять результаты вызовов некоторых встроенных в язык функций, включая методы работы со
строками (.concat(...), .substr(...) и т. д.). Кроме того, поддерживаются template strings. Это вот такие штуки:
`the value is ${x}`
И, как и раньше, если результат какой-то операции вычислить не удаётся, то результатом будет UNKNOWN. Такое может быть, если операция не поддерживается анализатором, или если неизвестно участвующее в операции значение. К примеру, если
надо вычислить x = a[3], а у a значение UNKNOWN, то и x станет UNKNOWN.
Многопроходный анализ
Алгоритм анализа, который был описан в предыдущем посте, делает один обход AST-дерева в глубину — это более-менее соответствует проходу по коду в прямом порядке «от начала до конца». Но в реальности инструкции программы не всегда выполняются в том же порядке, в котором они написаны в коде. Функции, например, не обязаны вызываться в том порядке, в котором они в коде написаны. Что если нам попадётся какой-то такой код:
function f() {
fetch(baseURL + '/users/list');
}
baseURL = '/blog/api';
f();
Здесь без объявления используется глобальная переменная baseURL.
Или такой:
function createRequestService() {
var apiVer, section;
function getSettings() {
fetch('/api/' + apiVer + '/' + section + '/settings');
}
function notifyOnline() {
fetch(
'/api/' + apiVer + '/' + section + '/status?online=true',
{ method: 'POST' }
);
}
function initialize() {
apiVer = '2.1';
section = 'shop';
}
return { getSettings, notifyOnline, initialize };
}
В обоих случаях переменные задаются по коду дальше, чем используются. Можно сказать, что потоки данных «текут» не всегда от начала программы к концу, иногда они «текут обратно». Для того чтобы с таким справляться, анализаторы делают несколько проходов анализа по коду. Чтобы алгоритм был легковесным, мы решили начать с двух проходов — предварительного, на котором анализатор постарается пособирать заданные значения везде где найдутся, и, следующего, основного. Причём обрабатывает AJAX-вызовы анализатор только на основном проходе, а предварительный используется только для сбора значений в программе. Для случаев в двух сниппетах кода выше этого уже хватит. Для каких-то более сложных случаев уже нет.
Вообще, классические статические анализаторы, построенные на стандартных принципах, делают так — они итерируются по коду, собирая на каждом проходе всё больше информации о его работе, и делают это до тех пор, пока процесс не сойдётся — точнее, пока очередной проход по коду не добавит никакой новой информации. Чтобы это всегда срабатывало, надо чтобы алгоритм анализа был построен особым образом — чтобы процесс гарантированно сходился. Даже когда он сходится, бывает такое, что сходится слишком долго. Кстати, напомню, что узнать больше про классические алгоритмы анализа можно по ссылкам из прошлого поста.
По тому, как сделан наш алгоритм, можно увидеть, что идейно он заточен под нахождение значений, которые на самом деле «константные» — которые задаются один раз, причём задаётся какое-то конкретное значение (зафиксированное в коде, а не пришедшее извне). Делаем расчёт на то, что «фиксированные» части запроса, которые и определяют, какая серверная ручка задействуется, будут заданы таким образом. Переменные же части, параметры запросов (юзернеймы, поисковые запросы, количества товаров и т. д.) в коде не найдутся, ну может они нам и не нужны.
Межпроцедурный анализ
Процесс отправки запроса часто вовлекает в себя работу нескольких функций. Надо понимать, как данные передаются между
ними. При разборе разных сэмплов реального кода, у нас это чаще всего выливалось в вопрос «какие данные приходят из аргументов
функции?». Мы решили не делать полноценный межпроцедурный анализ для всех функций программы, так как решили, что это
слишком тяжеловесно, а вместо этого решили сделать таргетированный анализ только для интересующих точек программы (позже
мы, кстати, несколько пересмотрели это решение, но об этом в другой раз). Возвращаемые значения обычных, объявленных
пользователем, функций мы решили для начала не искать — будем считать что они возвращают UNKNOWN. Сосредоточимся
на аргументах.
Чтобы анализ получился таргетированным и искал аргументы только там, где нужно, надо как-то понять: а где же нужно.
Для этого добавлено ещё одно специальное значение FROM_ARG. Оно в целом аналогично UNKNOWN, то есть это такое уникальное
значение, которое обозначает что-то, для нас неизвестное. Но оно дополнительно несёт информацию о том, что значение пришло
именно из формальных аргументов функции. При анализе тел функций анализ будет считать, что значения формальных аргументов
это FROM_ARG.

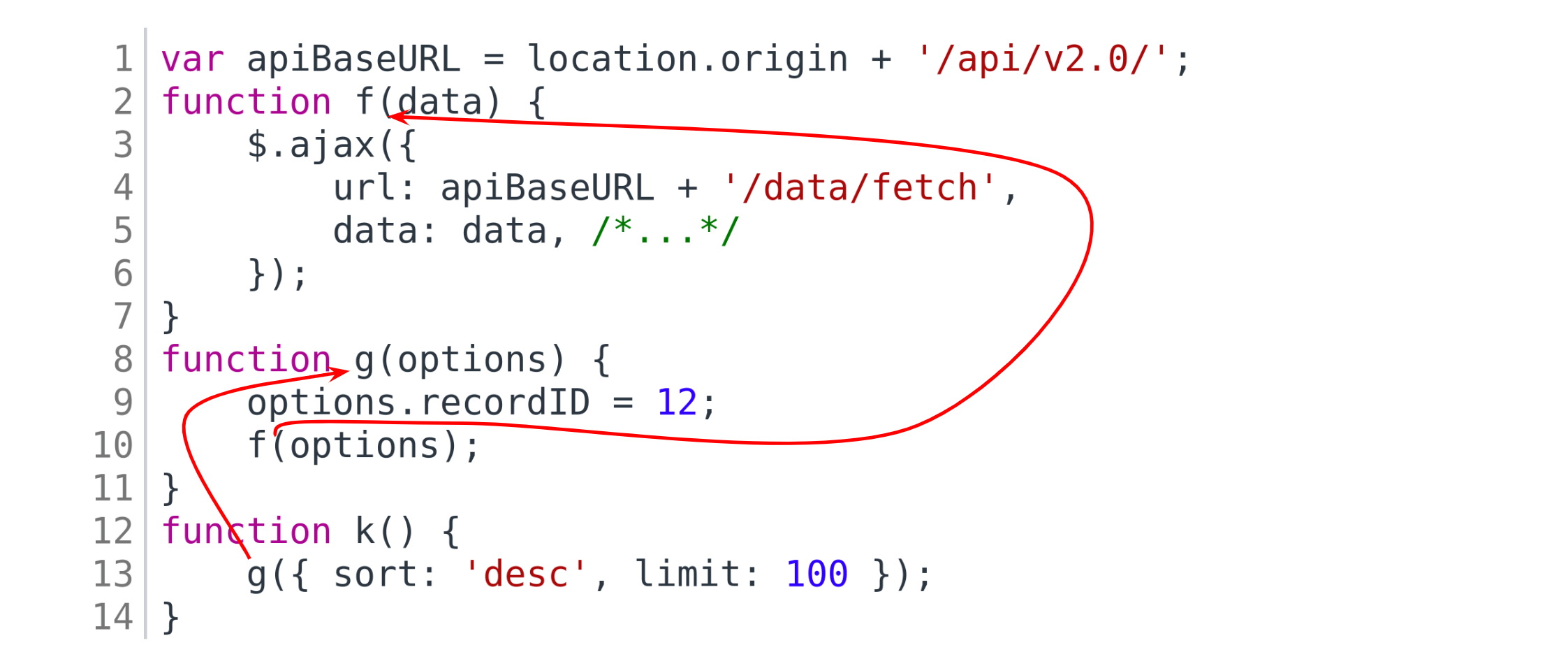
Если далее это значение дойдёт до места вызова AJAX-функции ($.ajax например),
то есть среди её аргументов будет FROM_ARG,
будет сделан вывод, что отправляемый запрос зависит от формальных аргументов функции, сделавшей AJAX-вызов. А значит,
надо поискать вызовы этой функции и то, какие там в неё передаются аргументы.
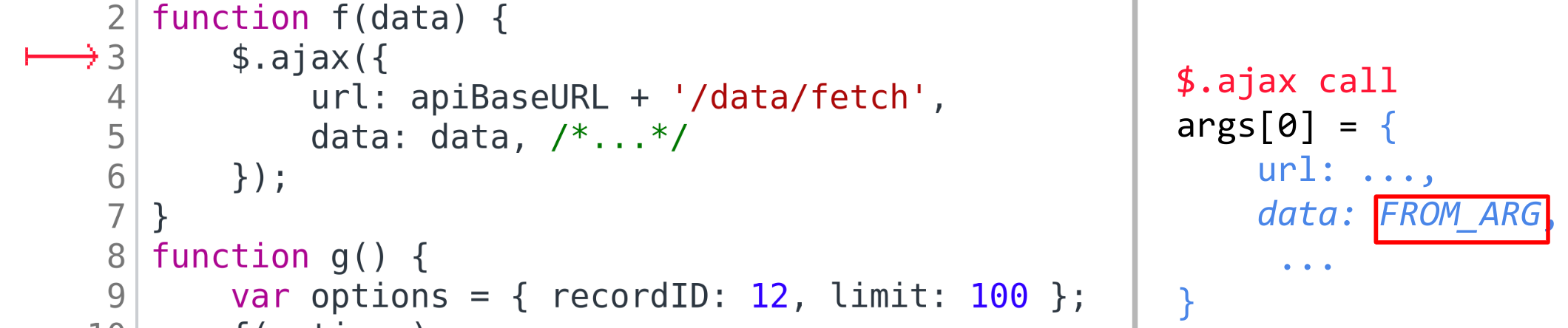
Как же будем искать? У нас есть наша мапа memory, в которой записаны значения переменных. При этом, как говорилось выше,
анализатор поддерживает функциональные значения. Возьмём функцию, чьи вызовы мы хотим найти (функцию f в данном случае),
пройдёмся по memory, взяв оттуда все переменные, указывающие на функциональное значение этой функции f. Ну то есть
в простейшем случае это будет просто переменная f, но в теории могут быть и другие переменные, если, например, было
присваивание типа other_func = f. Для каждой такой переменной пройдёмся снова по коду, ища места вызова, где на месте
вызываемой функции стоит эта переменная — их будем считать местами вызова этой искомой функции f. Вот для них нам хорошо
бы понять, какие аргументы в вызов передаются. Предположим, что найденное место вызова находится в какой-то другой функции,
фукнции g.
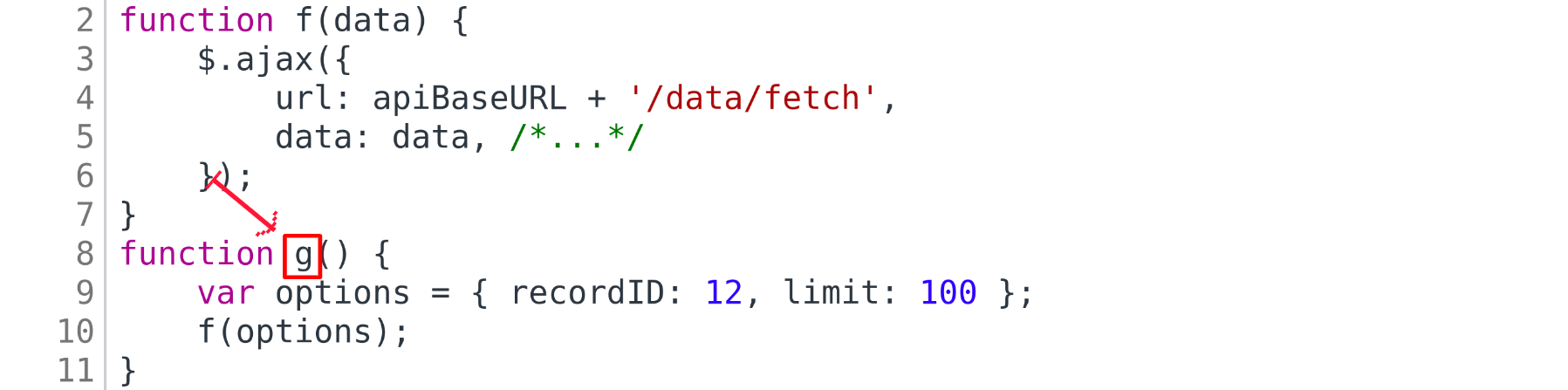
Проделаем анализ тела этой функции g — то есть обход её тела в глубину таким же образом, как и раньше, но, когда дойдём
до искомого места вызова f, то вычислим аргументы вызова и перейдём на начало кода f. В качестве значений формальных
аргументов f на этот раз возьмём не FROM_ARG, а фактические значения, которые только что вычислили — и дальше будем
выполнять анализ, обходя AST-дерево f от его корня. Таким образом мы «проэмулируем» вызов f с вычисленными аргументами.
Теперь, когда, обходя код f, мы дойдём до AJAX-вызова, то имеем шанс найти уже более точные аргументы этого вызова.
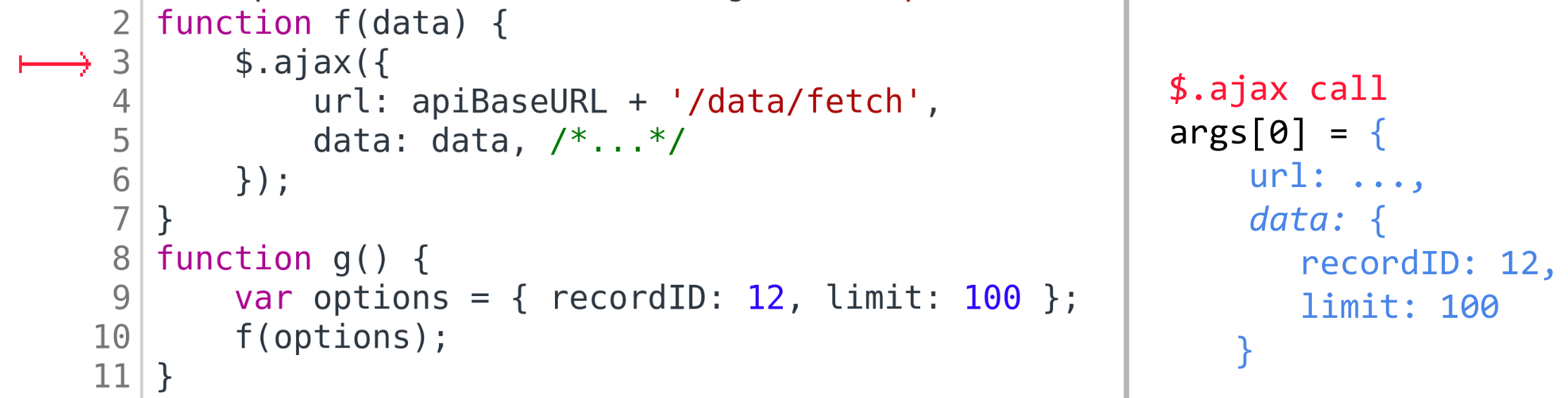
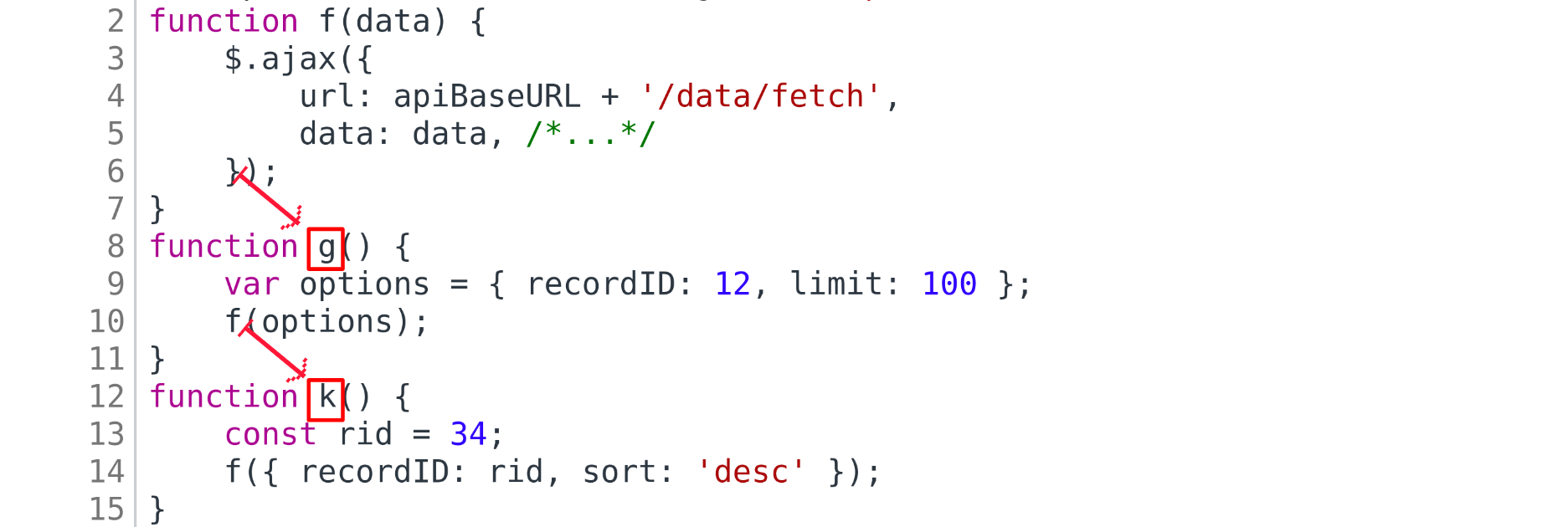
Такой анализ повторим для всех найденных мест вызова.
Ещё может быть, что вызов нашёлся вне какой-либо функции, на top level. Тогда проделаем анализ всего глобального контекста, ещё один обход всего кода — то есть обработаем этот случай так, как будто весь код находится внутри одной гигантской всеобъемлющей функции. Это довольно неоптимально, но для простоты используем сейчас такой вариант.
Цепочки вызовов
При поиске аргументов может потребоваться проанализировать цепочку больше чем из двух функций. Допустим, у нас была
какая-то функция f, которая делала AJAX-вызов, мы нашли её вызов в какой-то другой функции (g). Может быть, что
g передаёт в вызов f какие-то свои аргументы (или данные, зависящие от них). Мы сможем заметить это по тому, что
при анализе цепочки f -> g до AJAX-вызова снова дойдёт значение FROM_ARG. Это будет означать, что нужно попробовать
проанализировать цепочку большей длины — поискать в коде теперь уже вызовы g и повторить весь процесс с ними.
Такой анализ цепочек вызовов делаем после основных, обходящих весь код, проходов анализа. Таким образом анализ делается
более таргетированным — он сколько-то смотрит весь код вообще, но потом более тщательно анализирует интересующие участки.
Тут используется то, что AJAX-вызовы мы распознаём синтаксически, по именам — и поэтому «более интересные точки»,
начала цепочек вызова, получается выделять «дёшево», это не требует анализа само по себе. Но, с другой стороны, не
все AJAX-вызовы так найдутся. Кроме того, очевидно, этот метод сможет построить цепочки вызова только для вызовов
free-standing функций, точнее, вызовов, где функция задана как переменная, для которой анализатор смог найти значение.
Вызовы методов объектов (x.f()) таким алгоритмом не поддерживаются, как и вызовы функций, которые, скажем, были переданы
как аргументы (колбеков).
Специальные объекты
До этого и в этом, и в предыдущем посте термин AJAX-вызов использовался так, как будто это единый вызов функции,
получающий полную информацию о запросе, и отправляющий этот запрос. Но это не всегда так, иногда отправка запроса
из JS делается несколькими вызовами. На самом деле, первый браузерный интерфейс для отправки запросов из JS,
XMLHttpRequest, как раз работает так, что надо сделать несколько вызовов. Как минимум, надо создать объект класса
с помощью new, затем вызвать у созданного объекта метод .open(...), и затем .send(...). Как мы находим такое своим анализатором?
Если совсем кратко, идея такая — будем создавать специальный объект, который, можно сказать, моделирует экземпляр
этого XMLHttpRequest. Пусть этот объект будет одним из поддерживаемых анализатором значений и передаётся туда-сюда
при присваиваниях, обращениях к полям объектов и т. д. Будем создавать его когда увидим начало использования XMLHttpRequest,
и пусть этот объект запоминает данные, из которых формируется запрос. Встретив вызов someObj.open(...), проверим, не является ли someObj одним из наших специальных объектов, моделирующих
XMLHttpRequest. Если да, то пусть он «запомнит» вычисленные аргументы вызова open. Аналогично с методом .setRequestHeader(...), который выставляет заголовки. Встретив .send(...) для нашего объекта, также вычислим аргумент вызова — и в этот момент
у нас есть все данные, из которых формируется запрос. Ровно так мы делаем, кстати, для моделирования экземпляров FormData. Объекты FormData используются для составления наборов параметров, и у них, как и у XMLHttpRequest, есть состояние. Вызовы .append(...) или .set(...) добавляют в объект FormData параметры, а потом весь набор параметров отправится, когда объект будет передан в вызов .send(...) (или в вызов fetch(...)). Соответственно, у нас для этого заведён специальный класс FormDataModel, при обработке new FormData() заводится экземпляр этого FormDataModel, при обработке append и set в этот экземпляр записываются данные, при обработке AJAX-вызовов эти данные используются.
Так же можно было бы сделать и с XMLHttpRequest — вырабатывать специальное значение при обработке new XMLHttpRequest. Но мы делаем не совсем так.
Хак для XMLHttpRequest
При анализе реального кода мы заметили, что, при использовании XMLHttpRequest, вызовы .open(...) и .send(...) всё время находятся в одной и той же функции. В теории можно было бы завести объект XMLHttpRequest, сделать от него .open(...), после чего передать объект куда-то в другую функцию, где от него потом бы сделали .send() — но так никто не делает. Во всех случаях, что мы видели, всё происходит в одной и той же функции, и объект в обоих вызовах задан одинаково (часто это одна и та же переменная). Типа такого
// ...
xhr.open("POST", url, true);
// ...
xhr.send(data);
// ...
При этом new XMLHttpRequest() нередко выносят в отдельную функцию — вспомогательную функцию, которая создаёт объект и возвращает его, после чего им воспользуется другой код (такую вспомогательную функцию делают для поддержки старых браузеров, где нужно использовать класс ActiveXObject или что-то подобное). Будет обидно, если наш «data-flow» анализ не сможет проследить путь объекта XHR от new до места использования, и из-за этого отправка запроса не найдётся, в то время как open и send всё время идут вместе. Особенно учитывая, что возвращаемые значения пользовательских функций мы для начала решили вообще не моделировать. Поэтому решено было сделать так:
- Cоздавать объект, моделирующий
XMLHttpRequest, при виде.open(...). - Идентифицировать этот объект, не обращаясь к
memory, а просто по «виду» AST-вершины, отвечающей за объект, чей метод вызывается. То есть слева от.send(...)должно стоять то же самое (синтаксически), что и слева от.open(...).
За всё время эта эвристика ни разу не выдала false positive — да, может быть мы создадим «лишние» объекты на какие-нибудь вызовы open, но мы ни разу не видели такого совпадения, чтобы за этим open последовал send от того же объекта, и это не было использование XMLHttpRequest.
Чтож, пожалуй, для этого поста деталей достаточно. Спасибо, что дочитали его! Продолжение — в третьем посте про алгоритм анализа JS, вот тут.