Mining HTTP requests from client-side JS with static analysis — part 2
In the previous post
we looked at the basic idea behind the algorithm and even built a small analyzer based on it.
In this post I’ll talk a bit more about the principles our algorithm works on, including
how it determines function argument values and handles objects like XMLHttpRequest, plus
a few notes on the supported operations.
But still — how?
As I’ve already said, in terms of the core ideas, the algorithm is the same as what was described in the previous post. However, there are some distinctions.
Supported types and operations
The analyzer supports more types beyond just strings and UNKNOWN. Among them are objects, arrays,
numbers, boolean and undefined too (yes, as you probably know, there is a distinct type for undefined in JS).
For all these types, the analyzer can convert their literals (including things like [1, 2, 3] and {foo: "bar", abc: [true]})
into values and can compute the results of some operations involving these types. The set of supported operations
includes reading object/array fields (a[x], ob.prop) and writing them (a[x] = 123, ob.prop = v).
Functional values are also supported — when the analyzer processes function declarations
or function expressions (function literals, if you will) it also produces values that
can be stored in its memory.
So, for this code
function f() {
return 123;
}
var g = function(x) {
return x * 25;
}
var k = f;
var l = g;
The analyzer will figure out that variables f and k point to the first function (the one that returns 123) and
g and l — to the second one (that returns its argument multiplied by 25).
Each functional value contains a reference to the code of the corresponding function (to its AST, to be precise). This will be useful for interprocedural analysis which I’ll talk about later.
By the way, we can notice that values known to the analyzer can reside somewhere else except being kept directly as
values of the memory map — because the analyzer supports objects and arrays, values can “sit” in them, being their
members. Perhaps on some depth (with multiple layers of nested objects/arrays).
The analyzer can also compute the results of calls to some JS built-in functions, including
the methods that work with strings (.concat(...), .substr(...), etc.). Template strings are also supported.
And, as before, if the analyzer is unable to evaluate the result of some operation,
it will consider the result to be UNKNOWN. This can happen if the operation is
not supported, or the value, that the operation works on, is not known. For example,
if the analyzer tries to process x = a[3] and a has the value UNKNOWN, then x will also become UNKNOWN.
Iterative analysis
The analysis algorithm described in the previous post does a single AST traversal — this more-or-less corresponds to going through the code “from beginning to end”. But in reality, program instructions are not always executed in the order they appear in the source code. Functions, for instance, are not necessarily called in the order they are written. What if we have the code like this:
function f() {
fetch(baseURL + '/users/list');
}
baseURL = '/blog/api';
f();
A global variable baseURL is used here without being declared.
Or, like this:
function createRequestService() {
var apiVer, section;
function getSettings() {
fetch('/api/' + apiVer + '/' + section + '/settings');
}
function notifyOnline() {
fetch(
'/api/' + apiVer + '/' + section + '/status?online=true',
{ method: 'POST' }
);
}
function initialize() {
apiVer = '2.1';
section = 'shop';
}
return { getSettings, notifyOnline, initialize };
}
In both cases, variables have their values assigned later in the source code than they are used. We could say that data does not always “flow” from the beginning of the source code to its end, sometimes data “flows backward”. To handle this, analyzers make several analysis passes over the code. For the algorithm to be lightweight, we decided to start with two passes — one preliminary pass, where the analyzer will attempt to gather the assigned values everywhere, and the second, main pass. AJAX calls are processed only during the main pass, and the preliminary one is only used for gathering values. This will be sufficient for the two snippets above. For some more sophisticated cases this may become insufficient.
Classical static analyzers, built on textbook principles, often work as follows: they iterate over the code, gathering more and more information about it on each iteration, until the process converges — until the moment when an iteration adds no new information. For that to always work, an algorithm has to be built in a special way — so that the process is guaranteed to converge. Even if it does always converge, there are cases when it takes too long to wait until this happens. By the way, let me remind that you can use the references at the end of the previous post to learn more about the classical analysis algorithms.
By looking at the design of our algorithm one can tell that it is specialized for finding values that are actually “constant” — that are set once, and set with some concrete value (value fixed in the code, not coming from the outside). Our hypothesis is that “fixed” parts of the request, the ones that control which server endpoint will be invoked, will be set this way in the source code. We won’t find variable request parts, request parameter values (usernames, search queries, amounts of products, etc.) in the code, but maybe we don’t need them, after all.
Interprocedural analysis
The process of sending a request often involves several functions. We have to understand
how data flows between them. When examining code samples from real sites, this most often
translated for us to question “what data comes from the function arguments?”. We decided not to
do the full-fledged interprocedural analysis for all functions of the program because
we assumed that such analysis would be too heavyweight. Instead, we chose to do a targeted
analysis only for points in the program that we’re interested in (later we reconsidered this decision a bit,
but that’s a story for another day). We also decided to give up on determining the return values of regular,
user-defined functions — they all are considered to be UNKNOWN. Let’s focus on the arguments.
To make the analysis targeted, to make it search for arguments only in places we need,
we have to somehow understand: where do we need that. For that, a new special value
was introduced: FROM_ARG. This value is similar to UNKNOWN — this is a unique value
that signifies something unknown to us. But it additionally carries the information that
this value originated from formal function arguments. When analyzing function bodies
we will assume that values of all formal arguments are FROM_ARG.

If this value will then reach the AJAX call (for example, $.post or fetch),
that is, one of the arguments to that call will contain the value FROM_ARG, that
would mean that the request being sent depends on the formal arguments of the
function that made this AJAX call. Which, in turn, means, that we should look for
places where this function is called and try to determine which arguments are given
to it there.
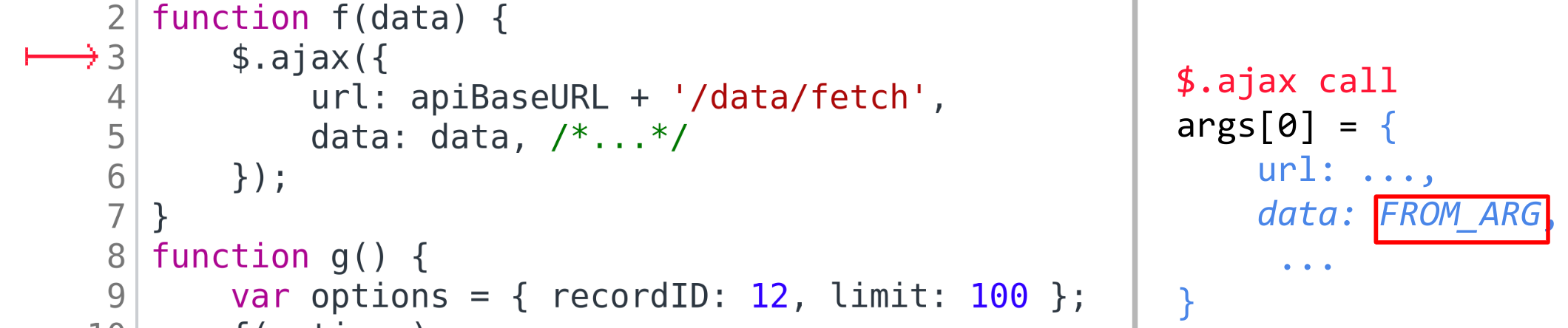
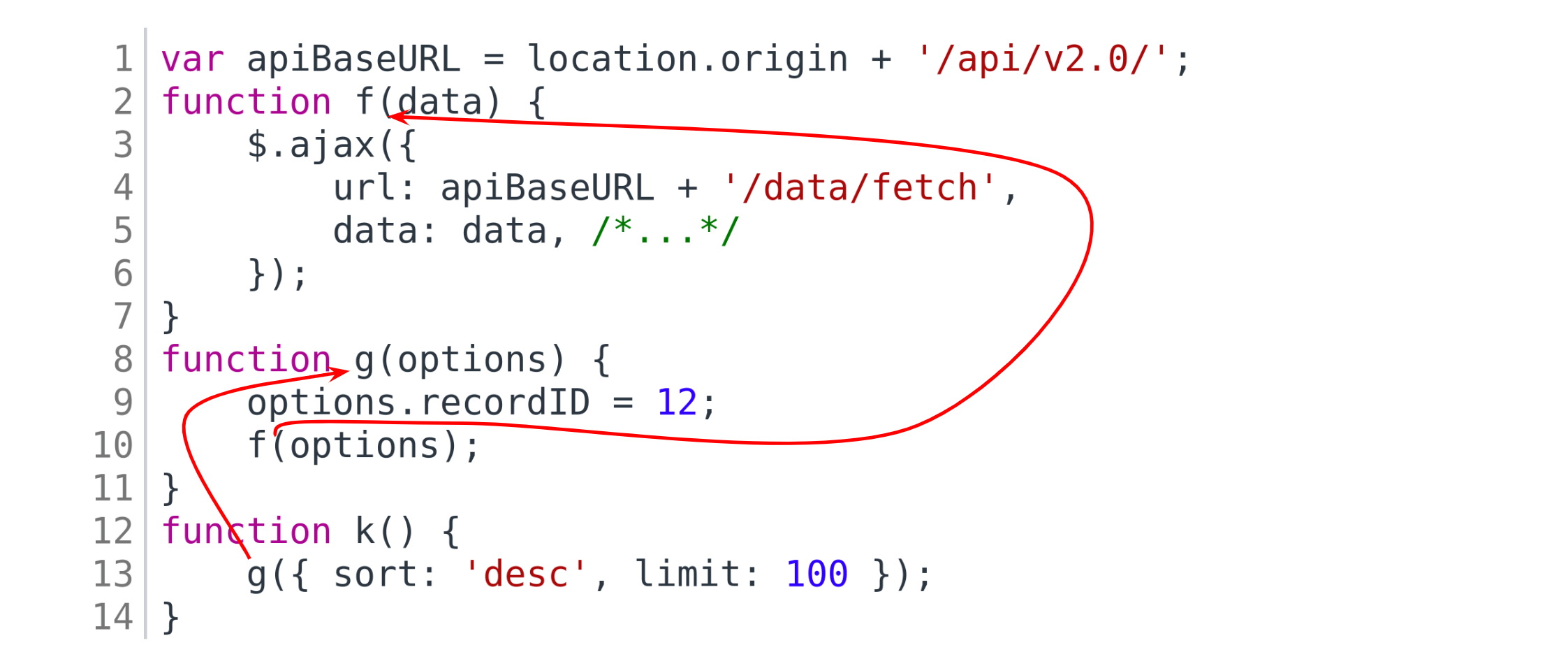
How do we search for those calls? We have our memory map, where all variables are stored. And
the analyzer supports function values. So let’s take a function, which calls we want to find (function f in this case) and
take from memory all variables pointing to the functional value of f. In the simplest case this
will be the sole variable f, but in more complex cases other variables might also be
picked if there were aliases: for example, if there was an assignment like other_func = f.
For every such variable (pointing to f) we will again traverse the code in search for call sites,
where this variable stands in place of the function being called — we will consider them
to be call sites of f. For them we would like to determine the arguments passed to the
call. Let’s assume that the found call site resides inside some other function, g.
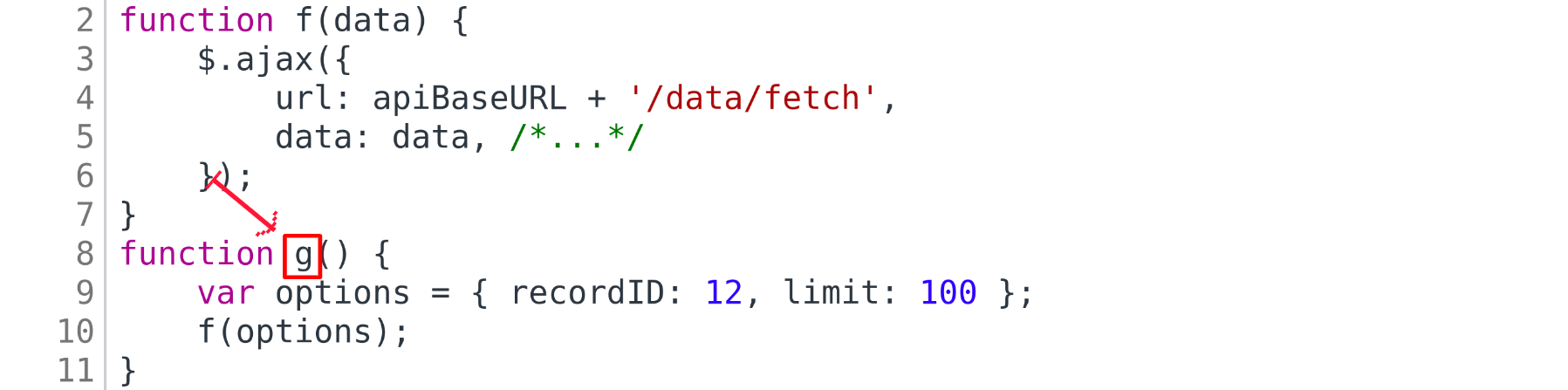
We will now analyze the body of this function g — traverse the AST of its body
in the same way as previous analysis traversals, but, when we meet the f call site we’re looking for,
we will evaluate its arguments and will move to the beginning of the f’s body. We will then
traverse the body of f, but instead of FROM_ARG we will take the computed arguments as
values of f’s formal arguments. And then we will analyze f, traversing the AST of its body.
This way we will “emulate” the call to f with computed arguments. Now, when we will reach
the AJAX call inside f, there is a chance that we will discover the more specific
arguments to that AJAX call.
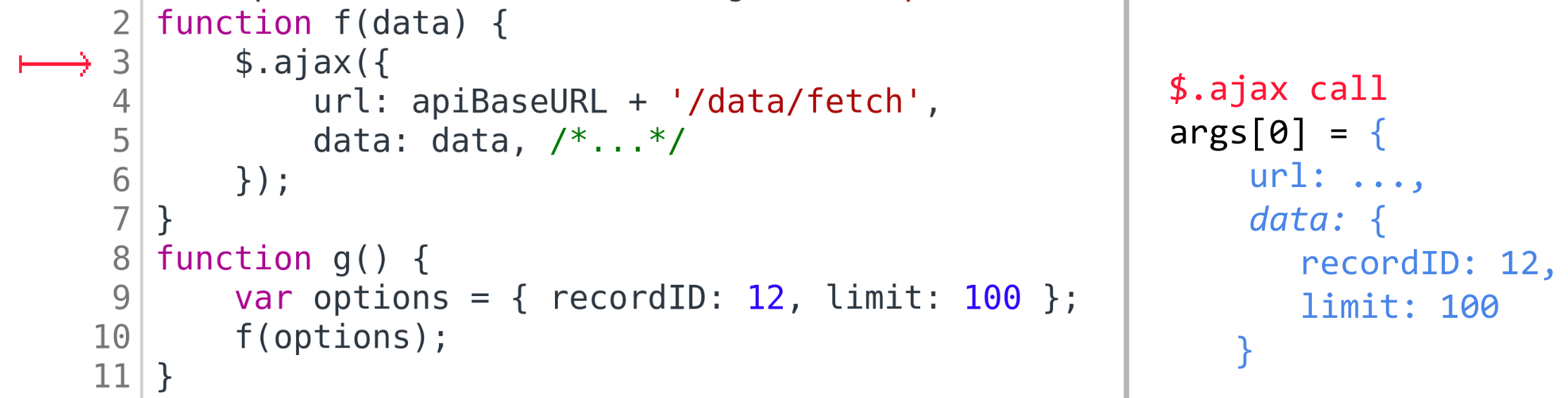
We will perform such analysis for all discovered call sites.
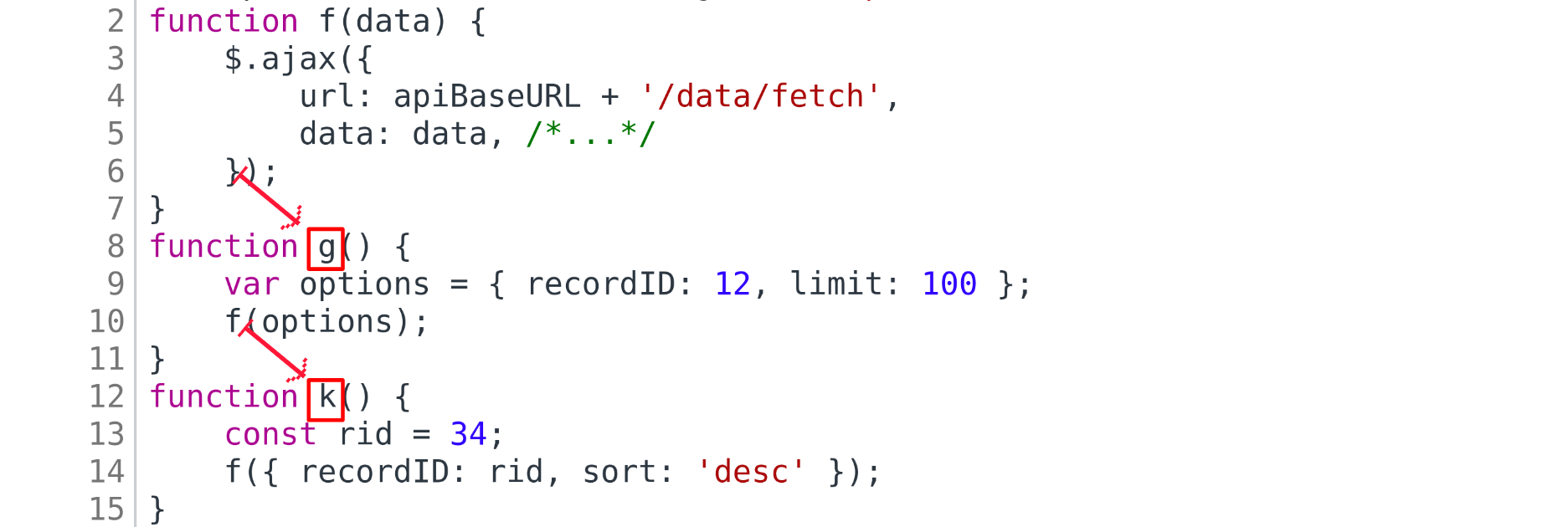
The call site might also be found outside any function, on the top level. In this case we will repeat the analysis of the global context, i.e. the whole code. In other words, this case is handled as if the whole program is contained in one large function. This is far from being optimal, but we’ll leave it like this now for the sake of simplicity.
Call chains
We might need to analyze call chains containing more than two functions while searching for
arguments. Suppose we had a function f that made an AJAX call, we found its call site
inside some other function (g). It may happen so that g passes some of its arguments
to the f call (or data depending on those arguments). We can detect that by seeing
that, when analyzing the chain f -> g, we still notice the value FROM_ARG reaching the AJAX call.
This would mean that we might have to analyze the longer chain — look for calls to g in the code
and repeat the process starting from each of them.
We perform this call chain analysis after the regular, base analysis passes are done (the ones that traverse the whole code).
This way, the analysis becomes more targeted — it examines the entire code for some time, but then
pays more attention to parts that we’re interested in. Here we use the fact that we detect AJAX calls
syntactically, using their names — so, “interesting” points, the places where call chains begin, are
“cheap” for us to find, finding them does not require code analysis by itself. But, on the other side,
we won’t find all AJAX calls this way. Besides, obviously, this method will only be able to
build call chains for calls to free-standing functions, or, to be more specific, calls, where the function
being called is given as a variable, for which the analyzer could find a value. Calls to object methods (x.f())
won’t be found by this algorithm as well as calls to functions that were, say, passed as arguments (callbacks).
Special objects
Previously the term AJAX call was used as if it is a single function call, that
accepts all the data needed to construct an HTTP request, and that sends that request.
But this is not always the case, sometimes sending a request from JS is done with
multiple calls. In fact, the first browser interface for sending requests from JS,
XMLHttpRequest, works just like that, it requires several calls to send a request.
At the very least, one has to construct an XMLHttpRequest instance using new, then
call its method .open(...) and then call .send(...). How do we find this with
our analyzer?
In short, the idea is to create a special object, which will model an XMLHttpRequest instance.
Such special objects will be among the values supported by the analyzer and will get passed
during assignments, field accesses, etc. We will create such an object every time we see
a beginning of XMLHttpRequest usage and these objects will memorize the request data put
into them. Upon seeing the call someObj.open(...) we will check whether the value of someObj
is one of our special XMLHttpRequest objects. If so, computed arguments to open will
be stored inside that object. The same is done with .setRequestHeader(...) calls.
When seeing the .send(...) call for our object, we will also compute its arguments —
and at this point we will have all the data that the request is made from.
The same technique is used, by the way, for modeling FormData instances.
FormData objects are used to create the sets of request parameters and, just like XMLHttpRequest,
they have their own state. Calls to .append(...) or .set(...) add
parameters to FormData object, and then the whole set of parameters will be sent
when this object is passed to .send(...) call (or to fetch(...)).
Accordingly, for this we have a special FormDataModel class. Its instance is created
when processing the expression new FormData() and, when the analyzer processes calls to
append and set, data is written into this instance. That data is used when
AJAX calls are processed.
We could do the same with XMLHttpRequest — create a special object when evaluating new XMLHttpRequest.
But in reality, we don’t do it quite like that.
A hack for XMLHttpRequest
When analyzing the real code we noticed that, when XMLHttpRequest is used, calls
to .open(...) and .send(...) are always located in the same function.
In theory it is, of course, possible to create an XMLHttpRequest instance, call its
.open(...) method, then pass this instance to some other function, where the method .send()
will be called — but no one does this. In all the cases that we’ve seen, everything happens
in the same function, and the object looks the same in both method calls. Like this:
// ...
xhr.open("POST", url, true);
// ...
xhr.send(data);
// ...
Meanwhile, new XMLHttpRequest() is often moved to another function — an auxiliary function
for creating this object and returning it, so that some other code can use it (such an auxiliary function
is used to support old browsers, where the class ActiveXObject or something like that is used instead of
XMLHttpRequest). It will be sad if our “data-flow” analysis fails to track the way of an XHR object
from new to the place where it’s used and the request being sent won’t be found because of that, while
open and send always come together.
Especially given that we’re not determining return values at the moment. So we decided to do the following:
- Create an object modeling
XMLHttpRequestwhen we see.open(...). - Identify this object not by accessing
memory, but solely by the “appearance” of an AST node that denotes an object, which method is called. That is, to the left of.send(...)there should be the same thing (syntactically) that to the left of.open(...).
This heuristic has never given us false positives — yeah, maybe sometimes we create “extra” objects
for some open calls, but there has never been such a coincidence that after that open the
call to send followed for the same object, and that was not an XMLHttpRequest usage.
Well, I guess that’s enough detail for this post. Thanks for reading it! For more, head over to the third post about the JS analysis algorithm — it’s right here.